Wordloom® Automated experience analysis from text data
- Natural language processing
- Topic modeling
- Data platform
Building the second generation of Iloom’s text analysis tool to analyse experience data.
Wordloom® is a custom built text analysis tool utilising the latest machine learning technologies.

"Our joint product development project with Emblica has been really fruitful: Iloom’s vast experience in social sciences and leadership has been a great match with Emblica’s top notch knowledge in data processing and deep learning!"
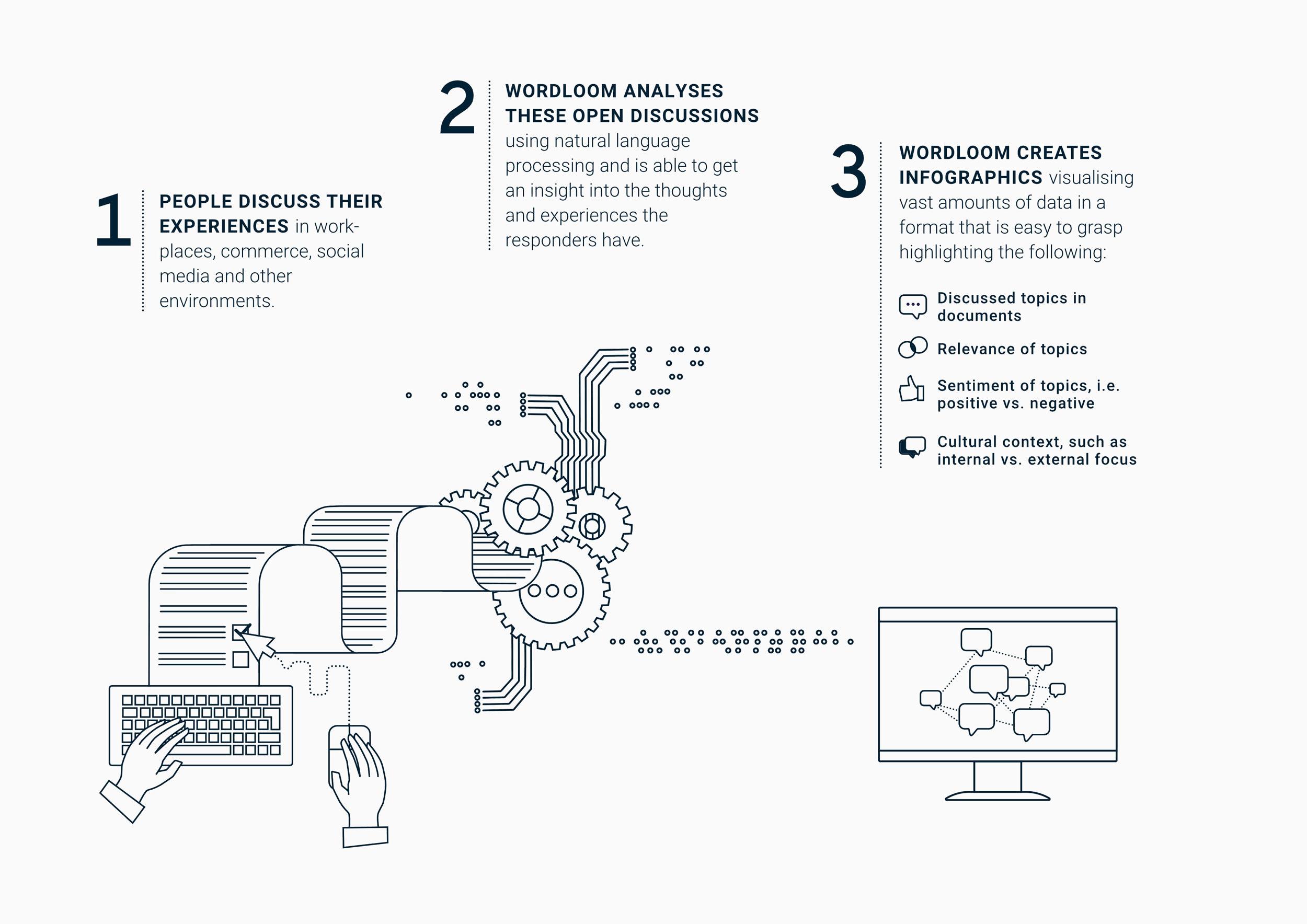
Sari Siikasalmi, CIO, IloomGetting to the core of human experience is essential in culture building, brand management and development of user experiences, but analyzing huge amounts of complicated data can take a long time. Could one get to the results faster by means of machine learning? Our friends at Iloom have done exactly that, making the analysis faster, more comprehensive and with the capacity to find serendipitous phenomena that might have been missed otherwise.

We helped Iloom to build the next generation of their tool, Wordloom®, which can be used to analyze people’s experience data, values and opinions from different sources. With natural language processing the system can scan large data sets and identify different topics, their sentiment, as well as point towards the underlying culture that drives these experiences. These results are then generated into a visual representation, which displays the survey results in an easy to read format.
The specialty of Wordloom® is the variety of use cases it offers, which are paired with context-sensitivity. The tool allows for multiple different natural language processing models to be run, e.g. topic modeling (with LDA) and deep models (such as BERT).
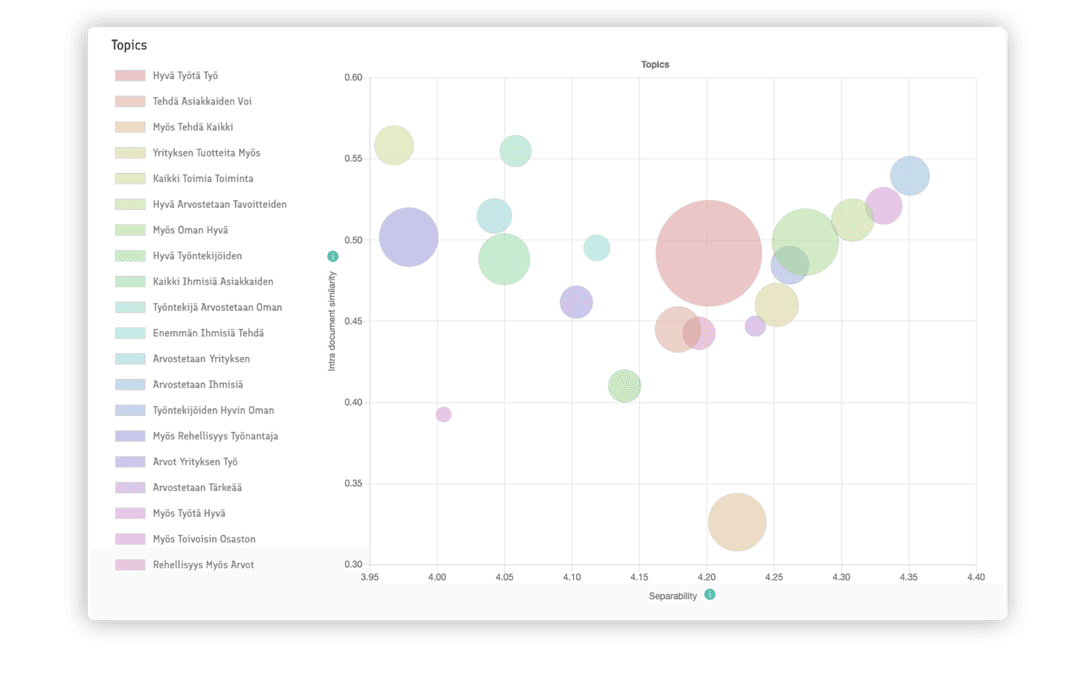
Wordloom® identifies the topics of discussion from each data set. This is done by utilizing LDA (Latent Dirichlet Allocation) which is one of the most established methods for topic modeling. LDA is a universal, generative statistical model that formulates a set of topics over a corpus of documents. It finds the topics of discussion unique to the analyzed corpus, by grouping the words that occur often together. These topics will include a list of the most relevant words for the topic, which are found within the analyzed data set. Additionally, each individual document has a distribution of multiple topics it belongs to. Therefore, all of the found topics are always tied to the data set and/or phenomena which is being researched.
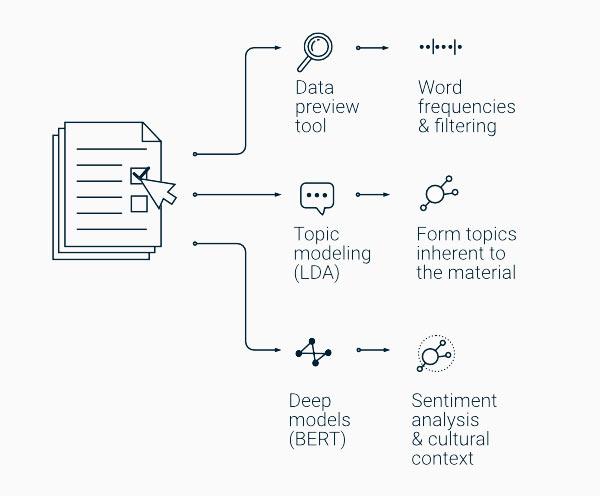
The tool can also be used to identify the sentiment or cultural context of the analyzed documents. This is made possible with BERT (Bidirectional Encoder Representations from Transformers), a transformer-based machine learning model developed by Google, utilized especially in contextual analysis. Wordloom® can also combine sentiment/culture analysis with topic modeling, which allows a more fine-grained view into the nature of each topic to gain a comprehensive understanding of the researched phenomena.

Wordloom design was partially funded by Business Finland.


