Problem
Understanding how machine learning can be utilised for text analysis
Understanding how machine learning can be utilised for text analysis
A learning project where ML models extracted topics and contexts of Finnish government programs
Government programs under the digital microscope
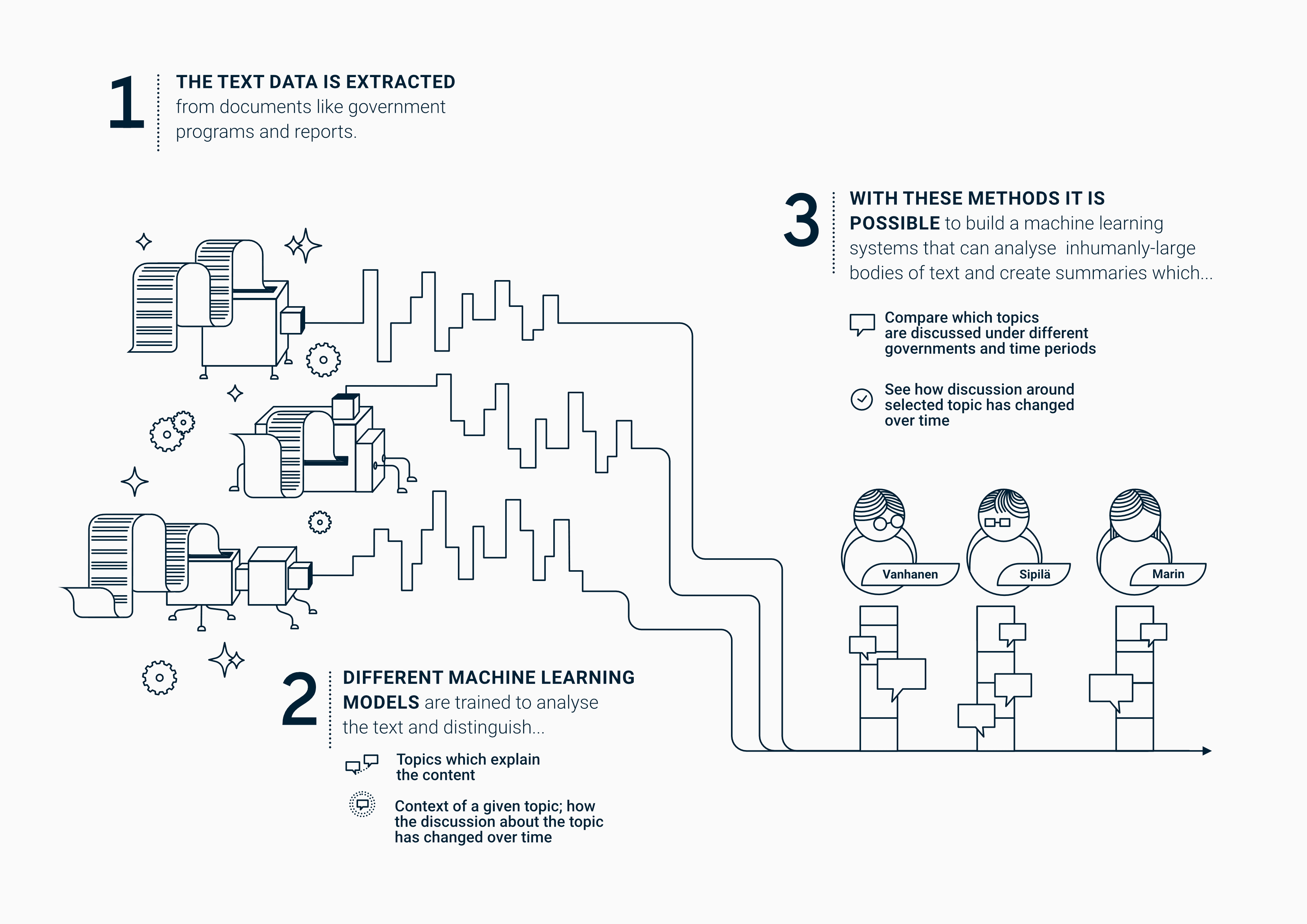
The Finnish Prime Minister's Office (Valtioneuvoston kanslia, VNK) commissioned a text analysis project from Emblica to educate them about the utilization of machine learning technologies. For this purpose, the Finnish government programs were analysed with ML methods to identify topics and contexts across the whole text material.
Learning every step of the way
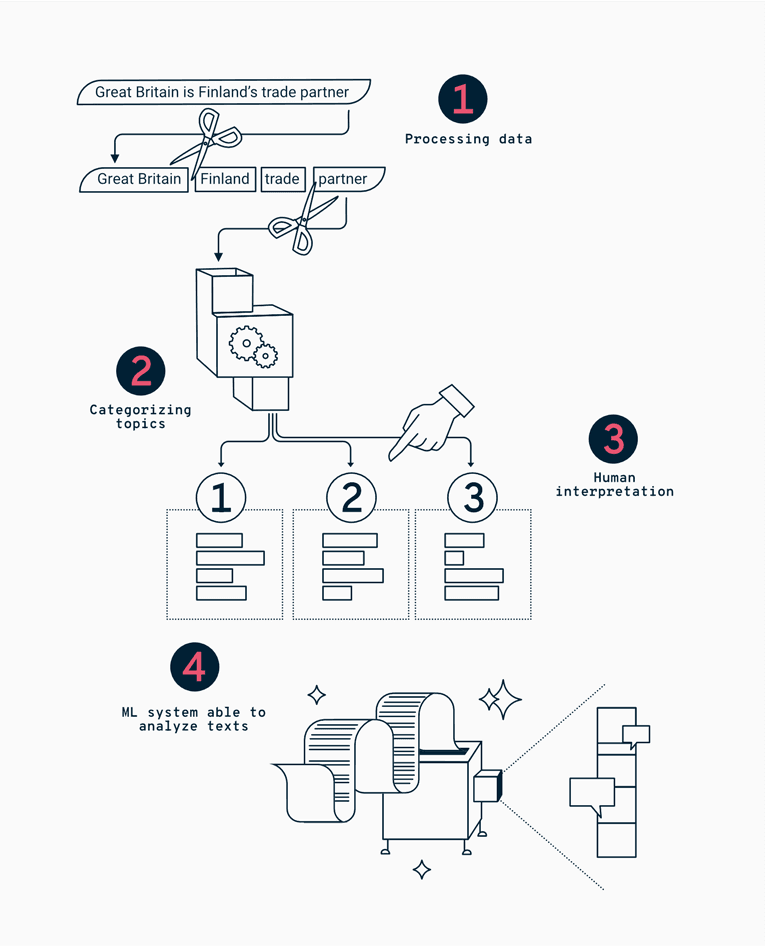
To help the client with their ML learning goals, Emblica team helped them understand the tech all the way from preprocessing the data, which lays the foundation for all successful data projects. For Topic modeling purposes, the data pre-processing in this project included the removal of unnecessary words from the material such as: “and”, “in”, “or” (stop words), and transforming the remaining words into their dictionary form (lemmatisation).
Extracting topics from the government programs
With the words in their dictionary forms, it was possible to do create groups of the words (topics) that often occur together within the original text material. These topics were then inspected and named by humans to give them inferred meanings. With this the model was ready to be used to detect and calculate the occurrences of topics in different text materials.
Extracting contexts from the government programs
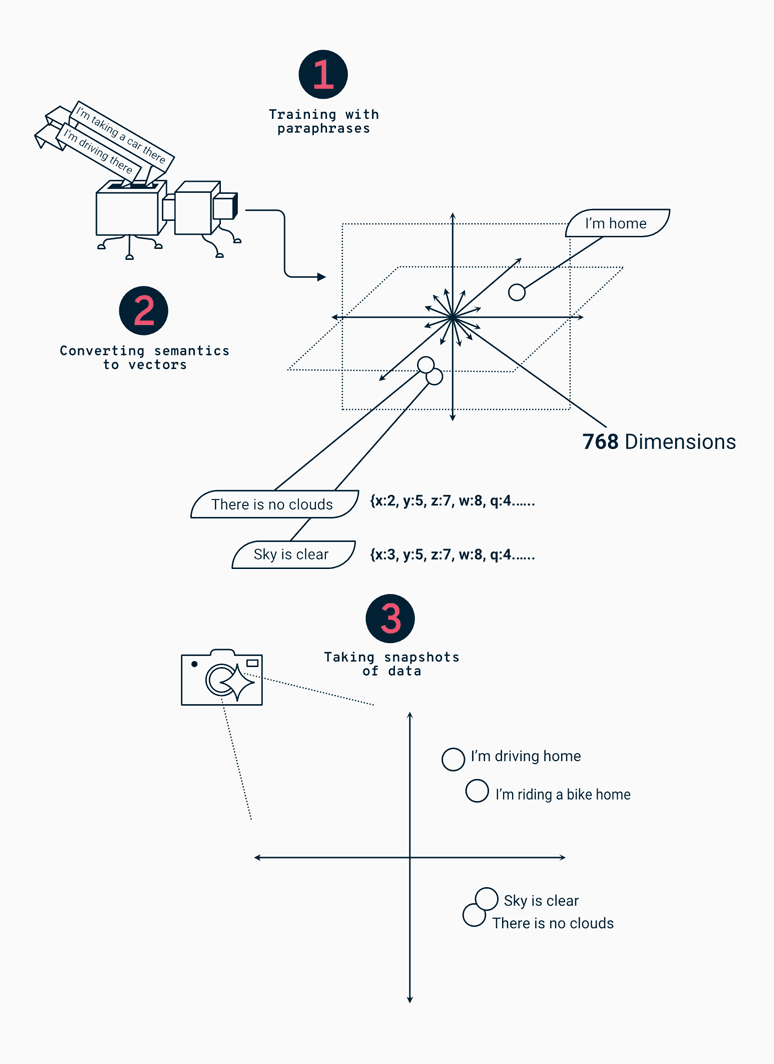
In order to train another model for detecting the contexts from government programs, a contextual model was trained by using sentences with similar semantic meanings (paraphrases). These semantics are then transferred into dimensions, which form the contextual space for the sentences. Similar sentences are close to each other in the space. Because the material included many dimensions (768 to be exact), the dimensions were reduced to 2-3 for visualisation and analysis purposes. This gave us the possibility to take snapshots and compare the similarities and the differences between contexts of the sentences.